##Etapas de un compilador
En la compilación o interpretación de un lenguaje existen distintas etapas, desde que nosotros tenemos nuestro input hasta que generamos una salida que nos sirve la para ejecución ya sea instrucciones de máquina u otro tipo de instrucciones que nos permitan de alguna manera interpretar esas instrucciones y poder tener un resultado de la entrada computacionalmente.
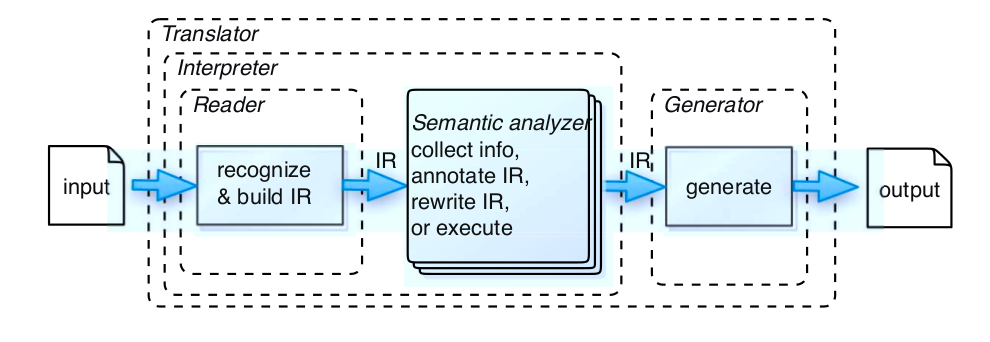
- Lector: que genera una estructura a partir de un input que es texto en genera, aunque puede ser a veces binario. Esta estructura la llamaremos IR.
- Generador: recorre la estructura y genera una salida a partir de este que puede serla salida misma de un compilador.
- Traductor: Un traductor leer una entrada de texto o binario y la traduce a otra salida que puede ser una traducción de un lenguaje a otro. Es un lector combinado con un generador. Ej. un profiler, refactor engine, etc.
- Intérprete: Un interprete lee, decodifica y ejecuta instrucciones desde simples cálculos hasta operaciones mas complejas, podemos ver esto en entornos como el de Ruby y Python cuyo interprete ejecuta un output final que es bytecode.
Existen muchos tipos de representaciones intermedias, la que nos interesa en particular por el momento es generar una construcción en forma de árbol llamada AST (Abstract syntax Tree). El AST sería un IR? No exactamente, si bien muchas IR son similares a los AST, los IR se refiere más al concepto de tener una representación de datos que está más asociada a una máquina abstracta en la que se realizará el análisis semántico, junto con las optimizaciones antes de pasar a la etapa de code generation. Nos interesa tener una construcción abstracta ya que nos permitirá trabajar con ella, y contendrá más información sobre el input que recibimos y no solamente texto. De esta manera será más fácil de saber el orden de ejecución y la información de cada uno de los nodos. Porqué vemos un AST como primer tipo de construcción abstracta? Porque es lo más simple para trabajar, si bien hay otro tipo de construcciones como ASG que nos permitirán trabajar más cómodo con lenguajes más complejos.
Por ej. si tenemos una expresión como this.x = y el AST que se forma una vez parseada la misma es:
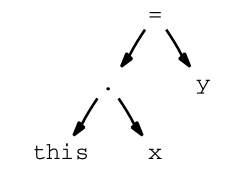
Aquí se puede ver que cada uno de los nodos del árbol representa un miembro de la expresión ya sea un identificador como x o y ó operadores como . o =. Como se remarcó antes estos nodos no solo tendrá definido el texto de entrada sino a que tipo pertenecen y el orden de evaluar la expresión dependerá de cómo es la estructura del AST, en este caso el orden de evaluación es de izquierda a derecha y de abajo hacia arriba. Existen distintos algoritmos para armar el AST y recorrer estos, luego pasaremos más links ya que nuestro objetivo al menos es la de aprender el paso para armar estas expresiones.
Volviendo al proceso que veremos hoy, el pipeline o pasos que veremos de la compilación son los siguientes:
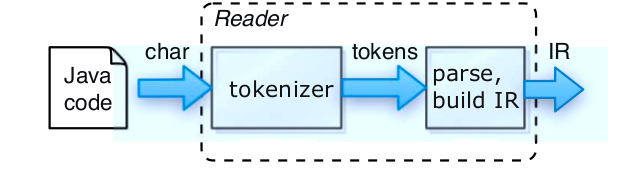
Solo veremos el lector, y este lector empieza por algo llamado tokenizer, que es esta fase?
##Tokenizer/Lexer
El tokenizer o analizador léxico es un módulo de nuestro compilador/intérprete/etc que lee nuestra entrada y separa esta en unidades que nuestro parser va a poder entender, dichas unidades son llamadas lexemas. Luego lo que hará el parser es validar la sintaxis de estos lexemas y decirnos si es correcta o no. Entonces si tenemos una entrada que es como
public static class Pepita { …..
generará lexemas de esta manera
public static class Pepita { …..
Las implementaciones que existen cuando se tokenizan se pasan al parser y este irá generando nuestra IR. Siempre lo recomendable es armar una IR si hacemos múltiples pasadas por el input, ya que la retokenización y reparseo del input para cada uno de los pasos es ineficiente y se complica el pasaje de información de cada uno de los pasajes. Múltiples pasadas nos permiten determinar errores de sintaxis en el analizador sintáctico que usará al IR para esto. Por ahora esto no es muy importante sino que hay que solamente tener en cuenta que el analizador léxico.
Otra cosa a tener en cuenta es que el analizador léxico tiene acceso a la tabla de símbolos que utiliza tanto este como el parser para generar la IR. Porque tiene acceso a esta tabla? Ahora explicaremos esto…
Antes de pasar al parser o analizador sintáctico pongamos un ejemplo de un pedazo de código en C como
fi ( a == f(x)) …
Vemos que cuando el analizador léxico lea la entrada no detectará a la palabra fi como una entrada inválida, y creará el lexema fi como un identificador…. pero si vemos nosotros esta expresión debería existir un if en vez de un fi…. entonces??? El analizador léxico no sabe determinar si sintácticamente es válida o no la expresión, sino que deberá pasarlo a otra etapa del compilador en este caso el parser que mediante la tabla de símbolos y reglas sintácticas determina que fi es inválido. Lo que sí puede hacer el analizador sintáctico es que si hubiese caracteres inválidos, no ascii o extraños a la entrada, o que no pueda pasar un lexema al parser porque es inválido en su construcción, entre en un modo llamado “modo de pánico”, en el que utiliza una estrategia en la que se eliminan caracteres sucesivos de la entrada hasta que el analizador pueda encontrar un token bien formado y generar una lexema correctamente. Hay otras estrategias de recuperación tales como:
- Eliminar un carácter del resto de la entrada
- Insertar un carácter faltante en el resto de la entrada
- Sustituir un caracter por otro
- Transponer dos caracteres adyacentes
Estas transformaciones se pueden probar antes de ignorar estas entradas inválidas.
##Gramáticas
Ahora el parser y el lexer usan una tabla de símbolos y el primero usa también reglas sintácticas para validar la entrada y generar una IR. Como se definen estas construcciones??
Por medio de una gramática. Y que es? es un conjunto de reglas sintácticas que definen a como es un programa válido para nuestro lenguaje.
En el próximo encuentro hablaremos más sobre los problemas que nos encontraremos cuando diseñemos nuestras gramáticas, por el momento, veamos que existen las gramáticas regulares y libres de contexto, las primeras describen lenguajes regulares y los libres de contexto lenguajes de este tipo.
Para que me sirve un lenguaje regular? el ejemplo más casual es para buscar patrones en un texto de entrada, mediante lo que conocemos como expresiones regulares y que permiten que expresar lenguajes regulares, sean finitos o infinitos.
Vimos algunos ejercicios con RegEx y fuimos probando en la siguiente página:
De aqui se puede buscar referencias sobre como utilizar las regex y con datos de muestra de entrada.
Otro lugar con referencia para regex se encuentra aqui: Regex
Luego de esto explicamos que existen casos en el que no podemos parsear un programa o entrada por medio de una expresión regular, por ej. un programa en Java. Para ello necesitamos una implementación que permita describir gramáticas libres de contexto, que tienen menos restricciones que las regulares, estas implementaciones son llamada generalmente parsers.
##Parsers
Es un analizador sintáctico que permite reconocer un lenguaje libre de contexto, descripta mediante una gramática de este tipo y genera un árbol de derivación o AST. Veremos como primer parser los parsers LL que son el ejemplo de parser más básicos y luego veremos ejemplos con parser combinators en Scala. Un tema a destacar es que los parsers realizan un análisis sintáxtico sobre nuestros tokens generados en el Lexer o tokenizador, y que ante una sintaxis incorrecta el parser puede generar un error y para el proceso de compilación hasta que se arregle la entrada correctamente y se vuelva a ejecutar el proceso nuevamente por parte del usuario.
###Parsers LL
El parseo una vez que ya esta tokenizada nuestra entrada es algo similar a cuando estabamos en primaria y hacíamos análisis sintáctico identificando verbos, sustantivos y modificadores directos e indirectos. El parser hace algo muy similar que es detectar a que tipo pertenecen cada uno de los lexemas y darle más información a nuestra entrada inicial además de determinar si cumplen las reglas sintácticas.
por ej.
return x+1;
Se analizará como
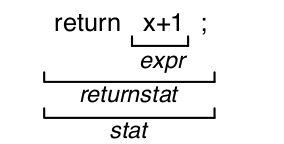
Una vez que se detecta que es válida esta sentencia se genera el AST, a algo como esto.
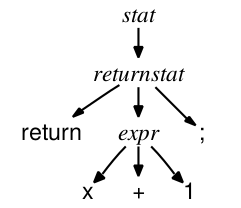
Se ve a simple vista que un AST tiene información sobre la sintaxis además del orden de ejecución que hará el intérprete o compilador más adelante, además de que ya sabrá cosas como el tipo en el caso del 1 que es un Int, o si fuese un argumento se podría saber cuando se ejecute, cual es su tipo cuando adquiera un valor y esta información es de utilidad para otros sistemas como el de sistema de tipos.
El parser LL(1) funciona de una manera muy simple, va a ir avanzando a partir de una lista de lexemas, de uno a la vez e identificando a que tipo de expresión estamos llegando. Este parser no puede mirar para atrás ( no tiene backtracking) y solo avanza hacia adelante. volviendo al ejemplo del return x +1;
el primer paso del parser será el de leer el primer token en este caso return
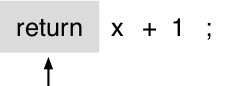
cuando se avance por el parser se detectara que return es del tipo return statement y de ahí parseará el siguiente lexema, teniendo en cuenta que debe ser una expresión.
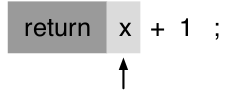
El siguiente lexema es un identificador que es una expresión válida, de ahí el resto de la expresión es una operacion (+) y un tipo entero (1) que forma x+1 que es una expresión, con el ; se finaliza la sentencia y se determina ya que la entrada es válida.
Entonces el flujo del parser sería algo como lo siguiente
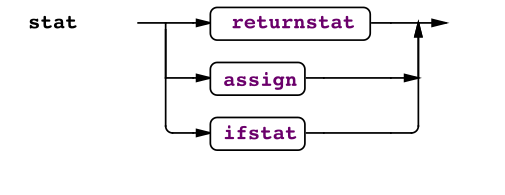
En donde se ve que cuando se detecta un return entrará en returnstat
Cuando se lea el X, el flujo del parser dentro de returnstat sera de este tipo:

Por lo que debe matchear con una expresión, viendo el parser de expr:
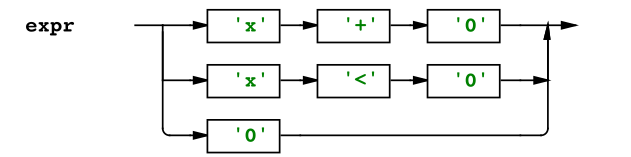
por lo que al detectar el token X, es válido aunque debería esperar otros dos tokens más… en este caso en vez de un 0 podría ser un token del tipo Int. entonces funcionaría para cualquier int. Este diagrama es para un caso más puntual pero se puede imaginar que no se tiene que restringir solo a x o 0 sino que puede ser del tipo identificador e Integer y el identificador es todo token que sea alfanumerico.
Suficiente sobre parsers LL, luego pasaremos algo de esto.
##Parser Combinators
Ahora ya sabemos sobre parsers, regex y gramáticas, lo que nos interesa es como escribir parsers en scala, por suerte en scala tenemos construcciones mucho más avanzadas que un parser de LL(1) que nos permitirá escribir parsers definiendo nuestras reglas gramaticales y lo que generará estas reglas. La construcción que utilizaremos en scala es algo llamado parser generators.
Que es un generator????, es una función de orden superior que combina dos funciones en una nueva función, entonces un parser generator es una función de orden superior que toma dos parsers y genera otro nuevo combinandolos.
De esta manera podremos combinar técnicas de distintos parsers para armar parsers mucho más completos y potentes, y tengamos que escribir menos código, y en el que en cada regla definimos que tipo de parser genera y cómo sería la entrada
Hay operaciones que podremos hacer con nuestros combinators cuando definamos las reglas de nuestro parser
- | es el combinator de alteración. es exitoso si la parte de la izquierda o derecha es exitosa
- ~ es el combinador secuencial. Que es exitoso si el operando de la izquierda parsea bien, y el de la derecha parsea bien para el resto de la entrada.
- ~> es el combinador que es exitoso si el operando de la izquierda parsea exitosamente seguido del de la derecha pero no incluye el contenido de la izquierda en el resultado.
- <~ es la reversa del anterior
- ^^ es el combinator de transformación. Si el operador izquierdo parsea bien, transforma el resultado usando la función de la derecha
- rep quiere decir que espera N- repeticiones del parser X donde X es el parser pasado como un argumento a rep.
Luego explicamos los ejemplos descritos en ILD-Parsers, explicamos los parsers de Morse, JSON, y S-Expressions y desarrollamos el de expresiones matemáticas.
Basandonos en el ejemplo que mostramos de JSOn parsers
Para definir un parser solamente debemos extender de la clase RegExParsers
trait JsonParser extends RegexParsersy creamos un companion Object para el trait, esto será para que podamos testear los métodos protegidos del trait en si en los unit tests.
El trait (mixin en realidad), fue definido con un apply en donde parsearemos toda la entrada y devolveremos un estado que puede ser Exitoso o Error, dependiendo del resultado final del parser
parseAll(body, input) match {
case Success(result, _) => result
case NoSuccess(msg, _) => throw ParseException(msg)
}Success y NoSuccess pueden verse como mónadas resultado, con estado, que permiten que de acuerdo a un resultado final, que puede ser en cualquier momento del parseo, dependiendo del resultado tomemos una acción, si sale todo bien se devuelve un resultado sino se tira una ParseException. Luego se definen las reglas, veremos que para las gramáticas se transforman a un objeto con el combinator ^^, y que el lado izquierdo de la regla puede verse como una regla gramatical y la de la derecha como el nodo del AST que se genera, de esta manera se ve claramente los pasos de entrada y salida que tendrá nuestro parser sin necesidad de meternos en la implementación en si del parser sino en como será nuestra entrada y que salida tendra si concuerda con la sintaxis.
protected lazy val body = "{" ~> repsep(property, ",") <~ "}" ^^ BPor último cuando resolvimos en clase el problema del Math Expression parser, vimos que había un problema de recursividad en nuestra implementación, si bien necesitamos preocuparnos por la sintaxis de entrada y lo que genera, necesitamos también conocer un poco sobre los detalles de los problemas que existen en gramáticas menos restrictivas y que existen más problemas y casos particulares, per veremos en el próximo encuentro sobre estos problemas.
##Tarea para Casa
- Armar un parser combinator para XML
##Bibliografía
- Aho, Lam, Sethi, Ullman. Compilers: Principles, Techniques, and Tools (2nd Edition) ISBN: 978-0321486813
- Cooper, Torczon Engineering a Compiler ISBN: 978-0120884780